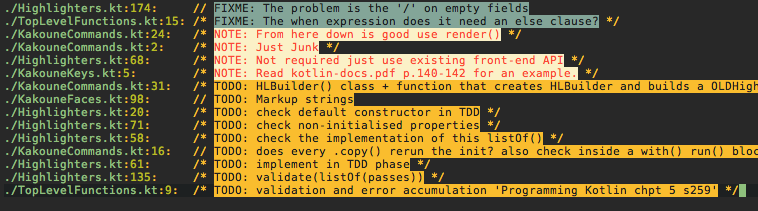
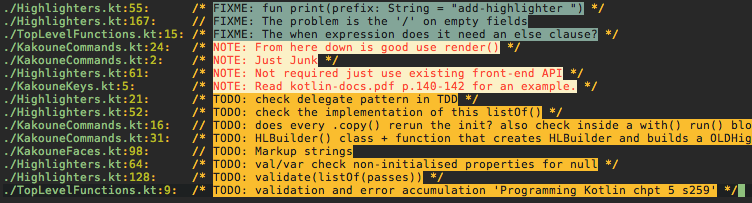
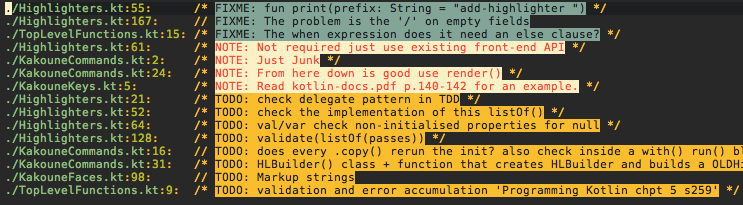
yields slightly better results, but still not the correct pattern. Look at the TODO’s 4xHighlighters.kt ordering displaced, also NOTE 2xKakouneCommands.kt numerically descending.
poor man’s solution. Same key pattern occurs three times so not very clever. If anyone got a better/clever solution please post it. Thanks.
Update 03
Cleaned it up a bit you can see the duplication in the key pattern. Not much of an issue, it works. Thanks @alexherbo2 for grep.kak. @robertmeta and @occivink you owe be a beer, it was a ruff road.
I don’t remember and don’t have ability to check, but doesn’t grep searches in the file the string after the colon, and changing amount of spaces (alignment) will make the jump fail?
Thanks for the reply Andrey,
the changes happen to the *grep* buffer not the grep search pattern except for the regex flag -E. I’m taking advantage of the hard work already done by @alexherbo2 in grep.kak.
Manipulation of the buffer still maintains an active jump list. The spaces are the distance from the gutter to the string of the original file.
The sort command uses each space to identify columns so sort -k 3 == column 3 == ‘F’,‘N’,‘T’.
grep.kak uses the flags -RHn == recursive, human (not byte), numerical.
So if you have any sed knowledge I think it might be the key to the buffer sort solution. I have no experience with sed and am reviewing sed1line.txt but honestly I’m lost when it comes to sed commands.
The sort command in the buffer is exhausted and provides no other functionality.
I cleaned this up a bit more now excludes the .git directory and *.md files on a recursive directory grep. Continues to work of the inbuilt functionality grep.kak and you can clone the snippet here. Pretty simple and very easy to extend for your language of choice. See kakoune explain the key-sequence for the regex sort.